When debugging containerized applications in Kubernetes, kubectl logs serves as your primary command-line tool for accessing container logs directly. Understanding how to effectively retrieve, filter, and analyze logs becomes essential for maintaining application health and resolving issues quickly, especially in multi-container environments where correlation across services can make or break your troubleshooting efforts.
This guide covers kubectl logs from basic usage through advanced troubleshooting scenarios, including real-world examples for single-container pods, complex multi-container environments, and integration with centralized logging solutions.
Understanding Kubernetes Logging Architecture
Kubernetes implements a distributed logging architecture where each node manages container logs through the kubelet agent. When containers write to stdout and stderr streams, the container runtime captures these outputs and stores them as JSON-formatted log files in /var/log/pods on each node.
The kubelet handles log rotation (default: 10MB size limit, 5 rotated files per container), lifecycle management, and API exposure. kubectl logs interfaces with the kubelet's API to retrieve these stored logs, supporting both historical access and real-time streaming.
This node-centric approach provides immediate access without external tooling, making it invaluable for rapid debugging. However, it has limitations in large-scale deployments: logs are stored only on individual nodes, making cross-cluster analysis challenging, and pods that restart frequently may lose historical log data during transitions.
How does kubectl logs work?
When you run kubectl logs, the client talks to the API server, which authenticates/authorizes and then proxies the request to the kubelet on the node where your pod runs; the kubelet reads the container’s stdout/stderr files and streams them back through the API server to you
Essential kubectl logs Commands
Here's a practical reference for immediate troubleshooting:
Basic log retrieval:
kubectl logs pod-name
Real-time log streaming:
kubectl logs -f pod-name
Multi-container pods:
kubectl logs pod-name -c container-name
Previous container instance (crucial for crashed pods):
kubectl logs pod-name --previous
All containers in a pod:
kubectl logs pod-name --all-containers=true
Time-based filtering:
kubectl logs pod-name --since=1h --timestamps
Limit output:
kubectl logs pod-name --tail=100
Label-based selection:
kubectl logs -l app=my-application
Export to file:
kubectl logs pod-name > application-logs.txt
Combined debugging approach:
kubectl logs -f pod-name -c api-server --tail=50 --timestamps
These form the foundation for effective log-based troubleshooting, providing immediate access to container output for debugging application behavior and performance issues.
Handling Multi-Container Pods
Multi-container pods present unique challenges, particularly in microservices architectures with sidecar containers, service meshes, and init containers.
Identify containers in pods:
kubectl describe pod multi-container-pod
Specify container explicitly:
kubectl logs multi-container-pod -c application-container
View all containers with prefixes:
kubectl logs multi-container-pod --all-containers=true --timestamps
Service mesh environments like Istio add complexity with sidecar proxy containers. Always verify container names to avoid viewing proxy logs instead of application logs:
# List containers
kubectl get pod istio-pod -o jsonpath='{.spec.containers[*].name}'
# View application logs, not proxy
kubectl logs istio-pod -c application --tail=200
Init containers require special attention since they execute before main containers start:
kubectl logs pod-name -c init-database-migration
Restart cycles in CrashLoopBackOff states make the --previous flag invaluable:
kubectl logs failing-pod -c problem-container --previous
This reveals the actual error that caused the container to crash, often unavailable from the current container instance.
Advanced Log Filtering and Time-Based Analysis
Effective troubleshooting requires filtering logs by time, content patterns, or specific events.
Time-based filtering:
# Last hour
kubectl logs api-server --since=1h
# Specific timestamp
kubectl logs api-server --since-time='2025-07-23T10:00:00Z'
# Last 50 lines with timestamps
kubectl logs api-server --tail=50 --timestamps
Combine with command-line tools:
# Filter for errors
kubectl logs application-pod | grep -i error
# Search with context
kubectl logs payment-service | grep -B 5 -A 5 "transaction_failed"
# Real-time monitoring
kubectl logs -f user-service | grep --line-buffered "slow_query"
Label-based aggregation:
# Multiple pods with labels
kubectl logs -l app=web-server --tail=100
# Namespace filtering
kubectl logs -l tier=backend -n production --since=30m
Complex filtering scenarios:
# Monitor startup issues across restarts
kubectl logs -f deployment-pod --previous --timestamps | grep "initialization"
# Export filtered logs
kubectl logs batch-job --since-time='2025-07-23T08:00:00Z' | grep -E "(ERROR|FATAL)" > error-analysis.log
These filtering techniques transform kubectl logs from a simple viewer into a powerful diagnostic tool for rapid issue identification within large volumes of log data.
Troubleshooting Common kubectl logs Issues
Understanding common problems and their solutions improves troubleshooting efficiency.
Empty log output despite running pods - Applications may not write to stdout/stderr:
# Check pod status
kubectl get pod problematic-pod -o wide
# Examine events
kubectl describe pod problematic-pod
# Verify processes
kubectl exec problematic-pod -- ps aux
Permission issues manifest as "access denied" errors:
# Check permissions
kubectl auth can-i get pods/log
# Verify bindings
kubectl get rolebinding,clusterrolebinding | grep $(kubectl config current-context)
Container restart cycles require the --previous flag:
# Check restart count
kubectl get pod crashing-pod
# Access failed instance logs
kubectl logs crashing-pod --previous
# Monitor events
kubectl describe pod crashing-pod | grep -A 10 Events
Multi-container specification errors:
# List containers
kubectl get pod multi-pod -o jsonpath='{range .spec.containers[*]}{.name}{"\n"}{end}'
# Specify container
kubectl logs multi-pod -c target-container
Network timeouts during streaming:
# Test with timeout
kubectl logs -f pod-name --request-timeout=30s
# Check connectivity
kubectl get endpoints kubernetes
Performance Considerations and Limitations
kubectl logs faces performance challenges in large-scale deployments:
API server load increases when multiple users query logs simultaneously. Each request travels through the Kubernetes API server to the kubelet, creating potential bottlenecks.
Storage overhead accumulates rapidly. Default kubelet configuration allows up to 50MB per container (5 files × 10MB each), but busy applications generate significantly more:
# Check log storage usage
kubectl debug node/node-name -it --image=busybox -- find /host/var/log/pods -type f -size +10M
Network latency affects retrieval performance, particularly with distant nodes. Real-time streaming becomes less responsive as cluster size increases.
kubectl logs works best for:
- Development and testing environments
- Immediate troubleshooting of specific pods
- Short-term log analysis
- Small to medium clusters (under 50 nodes)
Production environments with hundreds of nodes require centralized logging solutions for performance and comprehensive analysis.
Integration with Centralized Logging
While kubectl logs excels at immediate debugging, production environments need centralized logging for comprehensive management, retention, and analysis.
Log forwarding agents like Fluentd, Fluent Bit, or Promtail collect logs from all nodes:
# Check log forwarding status
kubectl get daemonset -n logging-namespace
kubectl logs -l app=fluent-bit -n logging-namespace
Hybrid workflows leverage both approaches:
# Immediate debugging with kubectl
kubectl logs -f problematic-pod --tail=50
# Historical analysis with centralized logs
# (using Loki query language)
{namespace="production", pod=~"problematic-.*"} |= "error" | json | level="ERROR"
Log correlation across microservices uses trace IDs:
# Extract trace ID
kubectl logs api-pod | grep "trace_id: abc123"
# Search centralized logs for same trace
Structured logging enhances both kubectl logs and centralized solutions:
{
"timestamp": "2025-07-23T15:30:00Z",
"level": "ERROR",
"service": "payment-processor",
"trace_id": "abc123def456",
"message": "Payment validation failed",
"error_code": "INVALID_CARD"
}
Get Started with SigNoz for Enhanced Kubernetes Monitoring
While kubectl logs provides essential debugging capabilities, comprehensive Kubernetes monitoring requires integrated observability solutions combining logs, metrics, and distributed tracing.
SigNoz offers comprehensive Kubernetes infrastructure monitoring built on OpenTelemetry, providing full-stack observability designed specifically for Kubernetes environments.
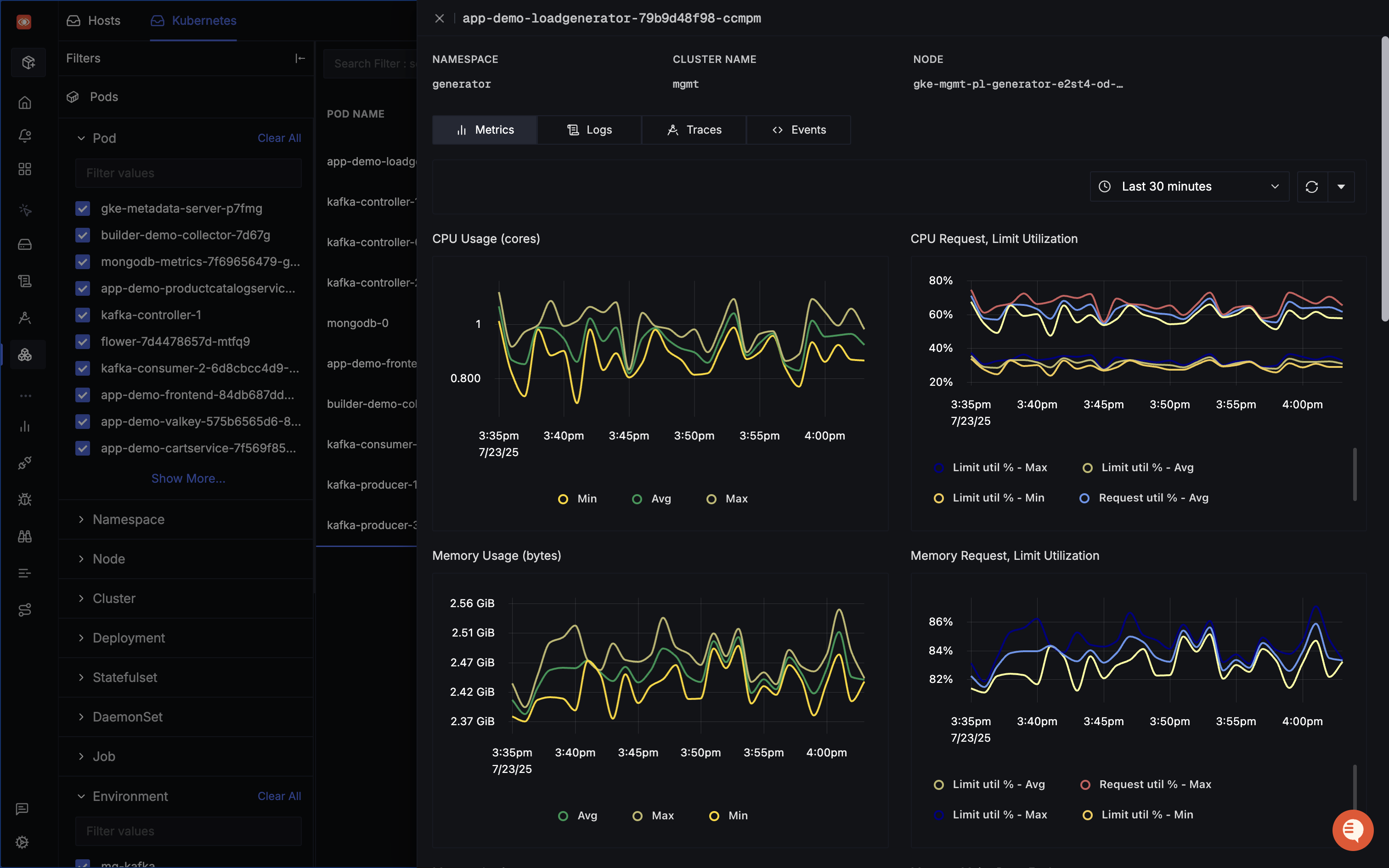
Key features that complement kubectl logs workflows include distributed tracing capabilities to identify root causes within clusters, advanced centralized log management that aggregates and analyzes logs from all services and pods, and telemetry data collection from key Kubernetes components like nodes, pods, containers, and services.
SigNoz follows OpenTelemetry semantic conventions like host.name, k8s.node.name, and k8s.pod.name to ensure consistent naming across telemetry signals.
You can choose between various deployment options in SigNoz. The easiest way to get started with SigNoz is SigNoz cloud. We offer a 30-day free trial account with access to all features.
Those who have data privacy concerns and can't send their data outside their infrastructure can sign up for either enterprise self-hosted or BYOC offering.
Those who have the expertise to manage SigNoz themselves or just want to start with a free self-hosted option can use our community edition.
Best Practices for Production Environments
Effective kubectl logs usage in production requires strategic approaches that maximize debugging efficiency while minimizing cluster performance impact.
Establish targeted access patterns:
# Namespace-specific queries
kubectl logs -l app=api-server -n production --tail=100
# Time-bounded analysis
kubectl logs pod-name --since=15m
Configure appropriate retention at kubelet level:
# kubelet configuration
containerLogMaxSize: "20Mi"
containerLogMaxFiles: 10
Implement structured logging for better analysis:
# Parse structured output
kubectl logs payment-service | jq -r '. | select(.level == "ERROR")'
Create debugging scripts for common scenarios:
#!/bin/bash
# debug-pod.sh
POD_NAME=$1
NAMESPACE=${2:-default}
echo "=== Pod Status ==="
kubectl get pod $POD_NAME -n $NAMESPACE -o wide
echo "=== Recent Events ==="
kubectl get events --field-selector involvedObject.name=$POD_NAME -n $NAMESPACE
echo "=== Recent Logs ==="
kubectl logs $POD_NAME -n $NAMESPACE --tail=50 --timestamps
Monitor resource usage:
# Check log storage
kubectl debug node/node-name -it --image=busybox -- du -sh /host/var/log/pods/* | sort -hr | head -10
Implement safe automation:
function safe_kubectl_logs() {
local pod=$1
local retries=3
for i in $(seq 1 $retries); do
if kubectl logs $pod --tail=10 2>/dev/null; then
return 0
fi
sleep $((i * 2))
done
echo "Failed to retrieve logs after $retries attempts"
return 1
}
Advanced Techniques and Hidden Features
Beyond basic retrieval, kubectl logs includes advanced features for complex environments:
Selective streaming from multiple containers:
# Monitor multiple containers
kubectl logs pod-name -c container1 &
kubectl logs pod-name -c container2 &
wait
Structured log parsing:
# Extract specific JSON fields
kubectl logs json-logging-pod | jq -r '.timestamp + " " + .level + " " + .message'
# Parse patterns
kubectl logs service-pod | grep -o '"request_id":"[^"]*"' | sort | uniq -c
Correlation with resource usage:
# Monitor resources while reviewing logs
kubectl top pod resource-intensive-pod &
kubectl logs -f resource-intensive-pod | grep "memory\|cpu"
Cross-pod correlation for distributed debugging:
# Extract trace IDs across deployment
kubectl get pods -l app=microservice -o name | \
xargs -I {} kubectl logs {} | grep -o 'trace[_-]id[":=][A-Za-z0-9-]*'
Custom processing and alerting:
# Real-time monitoring with alerts
kubectl logs -f critical-service | while read line; do
if echo "$line" | grep -q "CRITICAL\|FATAL"; then
echo "ALERT: $line" | mail -s "Production Alert" ops-team@company.com
fi
done
Conclusion
kubectl logs serves as an indispensable tool for Kubernetes debugging, providing immediate access to container output for rapid issue identification. From basic retrieval to advanced filtering and multi-container management, mastering kubectl logs significantly improves debugging efficiency in containerized environments.
Understanding when to use kubectl logs versus centralized logging solutions helps create balanced observability strategies meeting both immediate debugging needs and long-term operational requirements. Integration with platforms like SigNoz demonstrates how kubectl logs fits into broader observability ecosystems, providing the foundation for comprehensive application monitoring.
Whether debugging crashed pods, investigating performance issues, or monitoring application health, the techniques in this guide provide the foundation for effective Kubernetes log management and successful troubleshooting workflows.
